Semantic Network What Is The Relationship In Between The Accuracy And The Loss In Deep Discovering? This tradeoff in intricacy is why there is a tradeoff between prejudice and variation. A. The F1 rating is an action of a design's accuracy that takes both accuracy and recall right into account. The complication matrix can be made use of to compute a selection of metrics, such as accuracy, precision, recall, and F1 rating.
3 Techniques To Reduce Model Bias
Terashita et al. (2021) adapt the concepts of SGD-influence to approximate training data affect in generative adversarial networks (GANs). Extending representer point to other regularizers Yeh et al.'s (2018) representer factor formulation exclusively considers \( L_2 \)- regularized versions. Without effort, regularization's role is to encourage the design criteria to fulfill certain preferred homes, which may require using alternative regularizers. For instance, \( L_1 \) regularization is commonly made use of to cause sporadic minimizers. Basically, Yeh et al.'s (2018) representer point technique is very scalable and effective but is only suitable to identify habits that are noticeable in the model's last straight layer. Because of that, LOO has been related to make certain the fairness of algorithmic choices ( Black & Fredrikson, 2021).
Role Of Loss Functions In Machine Learning Formulas
Influence estimate can help in the selection of approved training instances that are particularly important for a given course generally or a single examination prediction specifically. In a similar way, normative descriptions-- which collectively develop a "basic" for an offered course ( Cai et al., 2019)-- can be picked from those training circumstances with the highest typical influence on a held-out recognition collection. In instances where an examination circumstances is misclassified, influence evaluation can identify those training instances that many influenced the misprediction. This way a depiction that does not have information concerning the secured quality is learned. We have seen that there is no simple method to choose thresholds on an existing classifier for various populations, to make sure that all definitions of fairness are pleased. Currently we'll examine a various technique that aims to make the category efficiency much more comparable for both designs.
On the other hand, in the case of a high preliminary offering, the company may endure in the future with reduced potential or reduced worker efficiency.
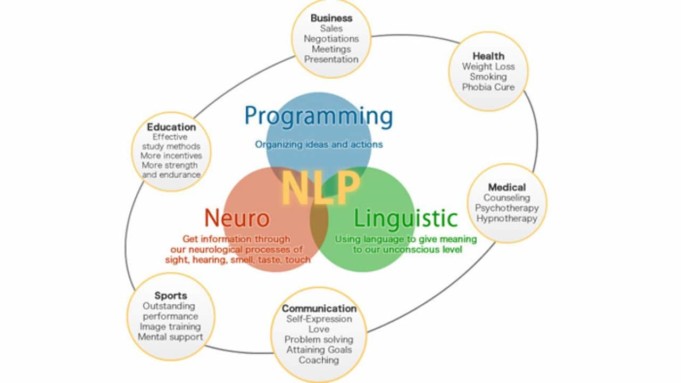
NLP can help individuals attain individual goals that surpass monetary and efficiency targets, boost employee morale, commitment, initiative, and success.
Finally, lack of actionable alternative profiles restricts the version's capability to generate other function value mixes that would assist to create a predicted result.
In truth, a set of varied counterfactuals may have adjustments of quality values for altering the prediction that is not adjustable to those worths [69]
In the complying with subsections, we represented our searchings for by addressing the first two study inquiries specified in Area 3.1. We adhered to mapping strategies from other write-ups to examine the major study fads in Ethical Artificial intelligence over the previous twenty years [33, 34] Our mapping methods involve determining pertinent publications by conducting a detailed search of four significant databases, consisting of ACM DL, IEEE Xplore, SpringerLink, and Scientific research Direct, focusing on papers on the justness concept. Let's code a complication matrix with the Scikit-learn (sklearn) library in Python. This suggests that we don't understand what our classifier is making the most of-- precision or recall. So, we use it in combination with various other assessment metrics, providing us a total photo of the result. Let's claim you intend to forecast the number of people are contaminated with an infectious infection in times before they reveal the symptoms and separate them from the healthy population (ringing any bells, yet?). Information sharing does not put on this post as no datasets were generated or analyzed throughout the existing study. In artificial intelligence, loss features quantify the level of mistake in between anticipated and real results. They give a way to assess the efficiency of a model on an offered dataset and contribute in optimizing version specifications throughout the training procedure. Inherent bias, also referred to as inherent prejudice, describes the bias fundamental in the examined information or issue rather than the predisposition introduced throughout the modeling or analysis procedure [62] In addition to all the discussed prejudices, we can observe inherent biases in several methods, such as prediction inconsistency and forecast falsification because of partial information. Prediction inconsistency is a various kind of predisposition dealt with as leave-one-out unfairness. Although a certain reason is yet to be discovered, scholars typically held most of the above prejudices responsible for forecast incongruity [84] This area details a restriction usual to existing gradient-based influence estimators that can create these estimators to methodically overlook very prominent (groups of) training instances. Unlike TracIn which uses a novel definition of impact ( 51 ), Chen et al.'s (2021) hypergradient information relevance analysis ( HyDRA) approximates the leave-one-out influence ( 8 ). HyDRA leverages the very same Taylor series-based evaluation as Koh & Liang's (2017) influence features. The vital distinction is that HyDRA addresses an essential inequality between impact features' assumptions and deep versions. As an instinct, an impact estimator that only takes into consideration the final model parameters belongs to just reviewing the closing of a book. One might be able to attract some big-picture insights, but the finer information of the tale https://storage.googleapis.com/life-coach/Career-coaching-services/teaching-methodologies/packedbert-exactly-how-to-accelerate-nlp-jobs-for-transformers-with.html are probably lost.
The Mystery of ADASYN is Revealed - Towards Data Science
An apparent effect then is the need for scientists and specialists to recognize the toughness and constraints of the numerous techniques so regarding recognize which approach ideal fits their specific usage case. This study is meant to give that insight from both empirical and academic perspectives. ( 61) is that training hypergradients influence the model criteria throughout all of training. By presuming a convex version and loss, Koh and Liang's (2017) streamlined formula neglects this extremely genuine result.
Hello! I'm Jordan Strickland, your dedicated Mental Health Counselor and the heart behind VitalShift Coaching. With a deep-rooted passion for fostering mental resilience and well-being, I specialize in providing personalized life coaching and therapy for individuals grappling with depression, anxiety, OCD, panic attacks, and phobias.
My journey into mental health counseling began during my early years in the bustling city of Toronto, where I witnessed the complex interplay between mental health and urban living. Inspired by the vibrant diversity and the unique challenges faced by individuals, I pursued a degree in Psychology followed by a Master’s in Clinical Mental Health Counseling. Over the years, I've honed my skills in various settings, from private clinics to community centers, helping clients navigate their paths to personal growth and stability.